Algoritmo Perceptron in python
In questi appunti sviluppo uno script in python per eseguire l'algoritmo perceptron. Per ogni riga di codice aggiungo una spiegazione dettagliata sul funzionamento.
Cos'è l'algoritmo perceptron? E' un algoritmo di classificazione dei dati del machine learning. E' una tecnica di apprendimento supervisionato che si basa sulle reti neurali.
Le librerie di funzioni di Python
Per sviluppare l'algoritmo del perceptron in python importo 3 librerie
import pandas as pd
import numpy as np
import matplotlib as mpl
A cosa servono?
La libreria pandas, numpy e matplotlib hanno funzioni aggiuntive rispettivamente per l'elaborazione dei dati etichettati, il calcolo matriciale e la rappresentazione grafica dei dati.
Nota. Se l'import restituisce un messaggio di errore, occorre prima installare le librerie. Per sapere come fare rimando alla lettura dei miei appunti su come installare pandas, numpy e matplotlib.
La preparazione del dataset
Scarico un dataset di prova su cui lavorare tra gli open data pubblici.
In questo caso prendo il classico dataset Iris.
Nota. Il modello Iris è una sorta di hello world del machine learning. E' un dataset di cui ho già parlato dettagliatamente in un esempio di Tensor Flow al quale rimando per ogni ulteriore spiegazione e approfondimento.
Evito di scaricarlo e lo assegno alla variabile ds dello script indicando direttamente il suo indirizzo url.
ds = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data')
La funzione read_csv della libreria Pandas mi permette di caricare in memoria un file in formato CSV.
Ora i dati del dataset sono salvati nella variabile ds.
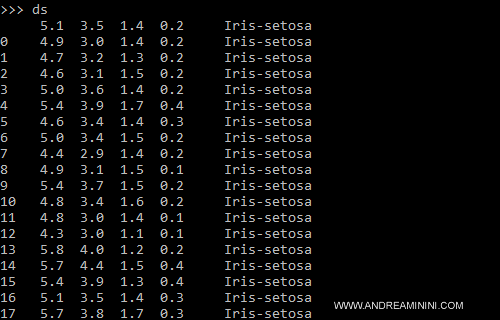
Il dataset è composto da 150 esempi
- da 1 a 50 sono esempi con etichetta Iris-setosa
- da 51 a 100 sono esempi con etichetta Iris-Versicolor
- da 101 a 150 sono esempi con etichetta Iris-Virginica
Per semplificare prendo soltanto i primi cento esempi Setosa e Versicolor.
Perché elimino l'etichetta Virginica? In questo modo elimino gli esempi etichetta Virginica e trasformo il dataset in una forma bidimensionale ( 2 etichette ).
Tramite il metodo iloc seleziono i valori (values) della colonna delle etichette nelle righe da 0 a 99.
La colonna delle etichette è associata all'indice 4 perché la prima colonna comincia con 0.
y=ds.iloc[0:99,4].values
Ora il contenuto del vettore y è il seguente:
La precedente istruzione seleziona i valori e li memorizza nella variabile y.
Ora la variabile y è un vettore con 100 elementi.
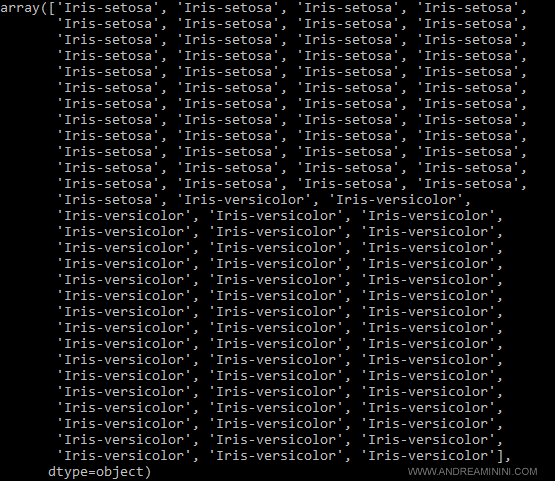
A questo punto trasformo le etichette "Iris-Setosa" in -1 tramite il metodo where di numpy.
A tutte le etichette diverse è, invece, assegnato il valore 1.
y = np.where(y == "Iris-setosa", -1, 1)
Il contenuto del vettore y è ora il seguente:
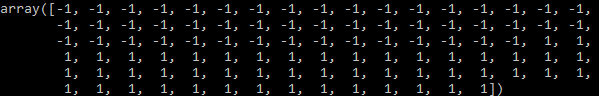
Adesso seleziono i valori (value) della prima (0) e della terza colonna (2) delle prime cento righe (0:99).
Poi salvo i valori nella variabile x.
x=ds.iloc[0:99, [0,2]].values
Ora il contenuto del vettore x è il seguente:
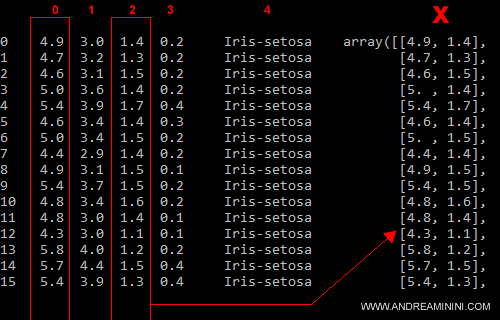
Adesso la variabile x è un array con due attributi ( non quattro ).
Gli altri due attributi li ho eliminati per trasformare la tabella in una forma bidimensionale.
Come programmare lo script Perceptron in python
A questo punto devo soltanto sviluppare lo script dell'algoritmo Perceptron.
L'algoritmo è suddiviso in tre parti: la definizione dei parametri iniziali, un ciclo esterno e un ciclo interno.

Per un approfondimento teorico sull'algoritmo Perceptron rimando alla lettura del modello MCP.
Definizione dei parametri iniziali
Assegno i parametri alle costanti eta e epoch.
In questo caso imposto 0.1 come fattore di apprendimento (eta) e un numero massimo di iterazioni ( epoch ) pari a 10.
eta=0.1
epoch=10
Poi inizializzo il vettore dei pesi w con un numero di elementi pari al numero delle colonne della matrice dataset (x1, x2) tramite la funzione shape() più uno per il valore x0.
In questo caso il dataset ha due attributi (x1, x2).
Pertanto, il vettore dei pesi W è un array composto da tre elementi.
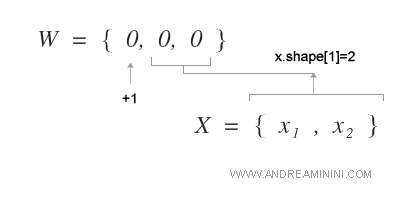
Tramite la funzione zeros() di numpy assegno zero a ciascun elemento del vettore w.
w = np.zeros(1 + x.shape[1])
Dopo l'inizializzazione il vettore w è un array con i seguenti valori:
>>>w
array([0 , 0, 0])
Infine inizializzo la lista errori dove registrare il totale cumulato degli errori in ogni iterazione (epoch).
errori = []
Inizialmente la lista è vuota.
Il ciclo esterno e il ciclo interno
Il core dell'algoritmo Perceptron è composto da due cicli nidificati.
Il ciclo esterno (i) itera dieci volte ossia un'iterazione per ogni epoch.
In questo caso epoch=10.
for i in range(epoch):
![]() errore = 0
errore = 0
![]() for xi, etichetta_corretta in zip(x, y):
for xi, etichetta_corretta in zip(x, y):
![]() z=np.dot(xi, w[1:]) + w[0]
z=np.dot(xi, w[1:]) + w[0]
![]() etichetta_previsione=np.where(z >= 0.0, 1, -1)
etichetta_previsione=np.where(z >= 0.0, 1, -1)
![]() modifica_pesi = eta * (etichetta_corretta - etichetta_previsione)
modifica_pesi = eta * (etichetta_corretta - etichetta_previsione)
![]() w[0] += modifica_pesi
w[0] += modifica_pesi
![]() w[1:] += modifica_pesi*xi
w[1:] += modifica_pesi*xi
![]() errore += int(modifica_pesi != 0.0)
errore += int(modifica_pesi != 0.0)
![]() errori.append(errore)
errori.append(errore)
![]() print("Epoch =", i,"| Errori =",errore,"\n")
print("Epoch =", i,"| Errori =",errore,"\n")
Il ciclo interno legge gli attributi x degli esempi e l'etichetta giusta ( etichetta_corretta ) dell'insieme di training.
Poi formula una previsione ( etichetta_previsione ) sulla base del vettore dei pesi W.
Se la previsione è sbagliata, aggiorna i pesi della riga del vettore W.
Spiegazione del funzionamento
Per ogni esempio dell'insieme di training ( ciclo interno ) lo script calcola la funzione di attivazione dell'algoritmo Perceptron.
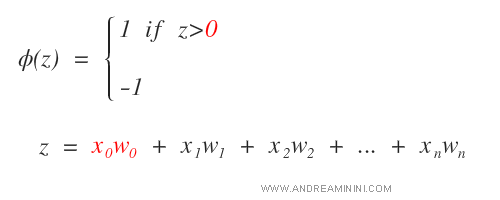
In un istruzione calcola la somma prodotto vettoriale z tramite la funzione dot() di numpy.
Il prodotto vettoriale è calcolato tra gli attributi dell'esempio xi e il vettore dei pesi dal primo elemento in poi (w[1:]).
Il primo elemento w[0] è aggiunto a parte perché ha un peso costante pari a 1.
z=np.dot(xi, w[1:]) + w[0]
Esempio
Se la riga del vettore degli attributi X è un array [ 4 , 1 ] e il vettore dei pesi W è [ 1 , 2 , 3 ] la funzione dot restituirebbe il valore 11 ossia (4·2+1·3).
>>> np.dot([4,1],[2,3])
11
Quindi z sarebbe pari a 12 poiché w[0]=1.
>>> np.dot([4,1],[2,3])+1
12
Nella riga successiva lo script calcola la funzione di attivazione φ(z).
Se z è maggiore di 0, assegna all'esempio l'etichetta 1, altrimenti 0,
etichetta_previsione=np.where(z >= 0.0, 1, -1)
A questo punto l'algoritmo ha sia l'etichetta giusta (etichetta_corretta) che l'etichetta calcolata (etichetta_previsione).
Può quindi verificare se la previsione è corretta oppure no.

Se la previsione è sbagliata, la differenza etichetta_corretta - etichetta_previsione è diversa da zero.
Quindi, anche, la variabile modifica_pesi è un numero intero diverso da zero.
In caso contrario, se la previsione fosse giusta, la variabile modifica_pesi sarebbe uguale a zero.
modifica_pesi = eta * (etichetta_corretta - etichetta_previsione)
In caso di previsione sbagliata (modifica_pesi<>0) i pesi W subiscono una variazione positiva o negativa a seconda dei casi.
w[0] += modifica_pesi
w[1:] += modifica_pesi*xi
In questo modo l'algoritmo Percpetron apprende dall'errore e modifica i pesi della rete neurale.
L'errore dell'esempio, se diverso da zero, viene aggiunto al totale degli errori registrati nell'iterazione in corso.
errore += int(modifica_pesi != 0.0)
Il ciclo interno si ripete per 100 iterazioni, una per ogni esempio dell'insieme di training.
Ecco un esempio di debug delle prime iterazioni.

Al termine del ciclo interno, quando l'algoritmo ha letto tutti i 100 esempi del vettore X, il totale degli errori viene registrato nella lista errori[].
errori.append(errore)
In questo modo posso poi verificare se la previsione migliora dopo ogni turno oppure no.
La variabile errore è azzerata all'inizio di ogni epoch (ciclo esterno). Se non la aggiungessi alla lista, perderei l'informazione.
A questo punto il ciclo interno ricomincia da capo per dieci volte ( epoch= 10 ).
Il risultato (output)
Al termine dell'elaborazione la lista degli errori[] è la seguente:
>>> errori
[2, 2, 3, 1, 0, 0, 0, 0, 0, 0]
Il numero degli errori è diminuito dopo ogni turno, ad eccezione della terza epoch, fino ad azzerarsi del tutto.
L'algoritmo ha progressivamente migliorato il modello predittivo sulla base degli esempi.
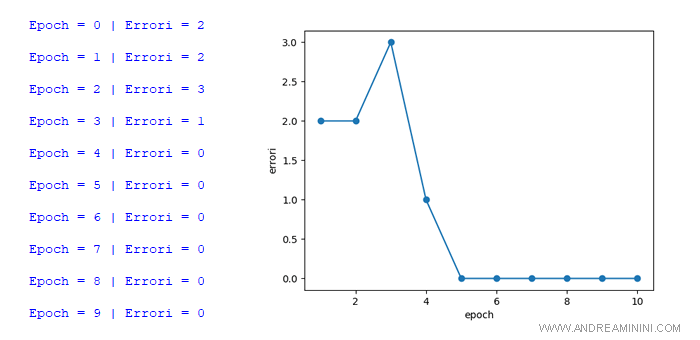
In questo modo l'algoritmo ha appreso dall'esperienza e dagli errori.
Il vettore finale dei pesi della rete neurale è il seguente:
>>>w
array([-0.2 , -0.98, -0.28])
La sua capacità predittiva è migliorata turno dopo turno.
Lo script Perceptron in python sembra funzionare correttamente.
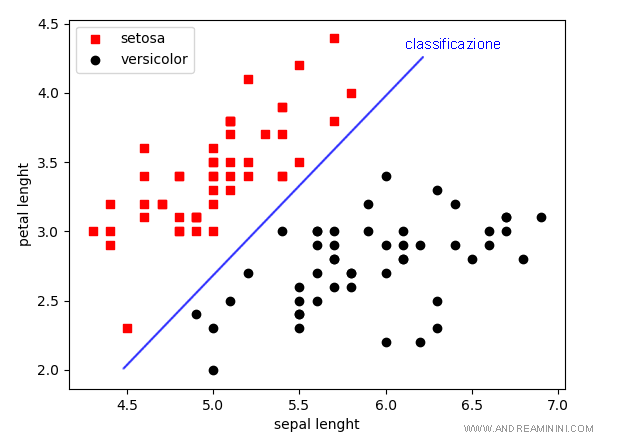
Il modello previsionale classifica tutti gli esempi con l'etichetta giusta.
Nota. In questo script ho evitato di programmare classi e funzioni per rendere più comprensibile il codice a chi non conosce la sintassi del linguaggio python. Secondo me, la forma procedurale è più universale e facile da leggere per chi sviluppa con altri linguaggi e per chi parte da zero. Inoltre, ho usato nomi di variabili mnemonici in lingua italiana. Pertanto, pur funzionando correttamente questo script è decisamente migliorabile in termini di efficienza e stile di programmazione.




