Come creare un dataset con Python
Per creare un dataset personalizzato su Python organizzo i dati di addestramento su un foglio elettronico qualsiasi (es. Excel, Calc, ecc.) e lo salvo in formato CSV.
Ad esempio, creo un dataset banale con cinque esempi e tre attributi (f1,f2,f3).

Se l'apprendimento si basa sul machine learning supervisionato, una colonna del foglio elettronico deve essere destinata alle etichette delle risposte corrette ("label") per ciascun esempio mentre le altre agli attributi (features).
Nota. La risposta (label) è 1 quando gli attributi f1 e f3 hanno valori alti. In caso contrario la risposta è 0. L'attributo f2 non influenza in alcun modo lo schema logico.
A questo punto carico il dataset su uno script in linguaggio Python.
Su Python uso la funzione read_csv() del modulo Pandas per importare il file CSV e salvarlo in una variabile qualsiasi (df).
import pandas as pd
df = pd.read_csv('temp.csv')
All'interno della variabile var è salvato il dataset per intero.

Tuttavia, in questa forma è ancora inutilizzabile da un algoritmo di machine learning.
Estraggo la colonna "label" del dataset e la salvo in un'altra variabile di Python (y_train).
y_train= df['label']
Ora la variabile y_train contiene le risposte esatte del dataset di addestramento.
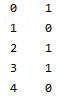
Poi estraggo le altre colonne del dataset senza la colonna "label" e le salvo in un'altra variabile (x_train).
x_train = df.drop('label', axis=1)
Ora la variabile x_train contiene gli esempi e gli attributi del dataset di addestramento.

Il dataset è pronto per addestrare un modello.
Un esempio di addestramento
Per semplicità carico l'algoritmo di addestramento Perceptron dal modulo Scikit-Learn.
Qualsiasi altro algoritmo classificatore di supervised ML sarebbe andato bene.
from sklearn.linear_model import Perceptron
ppn = Perceptron(max_iter=40, tol=0.001, eta0=0.10, random_state=0)
Infine addestro il modello tramite la funzione fit() di Scikit-learn.
Come argomenti uso le variabili x_train (esempi e attributi) e y_train (risposte corrette).
ppn.fit(x_train, y_train)
La funzione fit() crea il modello previsionale, ossia un classificatore che è in grado di classificare le istanze secondo l'addestramento ricevuto.
Come capire se il modello funziona?
Al termine dell'addestramento verifico se il modello ha capito lo schema nascosto (pattern) nei dati di addestramento.
Chiedo al modello di predirre e classificare alcuni esempi di test (diversi da quelli di training) tramite la funzione pred() di Scikit-learn e verifico se risponde correttamente.
Istanza 1
Nella prima istanza passo al modello un vettore [f1,f2,f3] con un valore alto (7) sulla prima caratteristica.
ppn.predict([[7, 4, 2]])
Il modello classifica correttamente l'istanza nella classe [1].
[1]
Istanza 2
In un'altra istanza passo al modello un valore basso (3) sulla prima feature.
ppn.predict([[3, 4, 2]])
Il modello classifica correttamente l'istanza con la classe [0].ù
[0]
Il modello è stato addestrato con il machine learning tramite gli esempi contenuti nel foglio elettronico.
Come si crea un dataset senza csv
Posso creare il dataset anche senza passare per il CSV.
L'importante è generare una tabella di apprendimento tramite la funzione DataFrame() di Pandas.
Esempio
La tabella dell'esempio precedente posso crearla manualmente in questo modo
d1 = {'label': [1, 0,1,1,0], 'f1': [7, 1,8,6,2], 'f2': [1, 2,3,1,2], 'f3': [3, 0,6,5,0] }
df = pd.DataFrame(data=d1)
Dopo l'assegnazione la variabile df contiene i seguenti valori
Il resto dello script è lo stesso.
E così via.




