Come rappresentare le regioni decisionali dei classificatori in python
Quando si elabora un dataset con un algoritmo di machine learning, è utile rappresentare le regioni decisionali della classificazione tramite la funzione plot_decision_regions() della libreria mlxtend.
Questa funzione mi permette di visualizzare il dataset su un diagramma a due dimensioni ed evidenziare le regioni individuate dall'algoritmo classificatore ( es. Adaline, Perceptron, ecc. ). 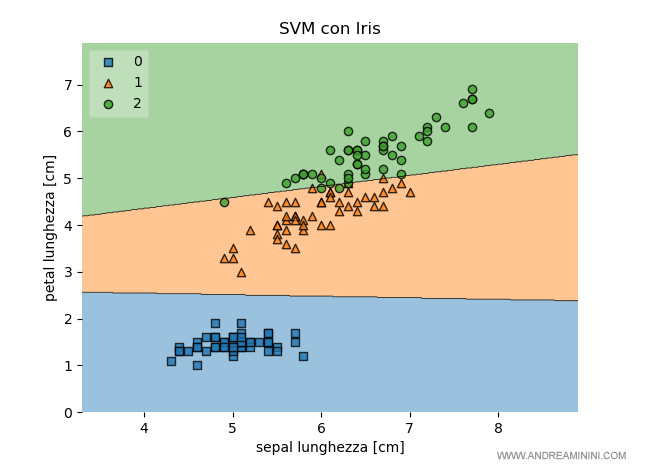
Per usare questa funzione devo prima installare la libreria mlxtend sull'interprete python tramite il comando PIP.
Così come accade per tutti i moduli aggiuntivi esterni.
Un esempio pratico
In questo script uso la libreria scikit-learn per addestrare la macchina a classificare correttamente gli esempi del dataset Iris tramite svm.
- from sklearn import datasets
- from sklearn.svm import SVC
- # Carico il dataset Iris
- iris = datasets.load_iris()
- X = iris.data[:, [0, 2]]
- y = iris.target
- # Addestro il classificatore
- svm = SVC(C=0.5, kernel='linear')
- svm.fit(X, y)
Per visualizzare graficamente la classificazione uso la funzione plot_decision_regions().
La carico in memoria con il comando from import di python.
from mlxtend.plotting import plot_decision_regions
Poi calcolo i dati di plotting tramite svm con scikit-learn (sklearn)
plot_decision_regions(X, y, clf=svm, legend=2)
Per visualizzare il risultato della classificazione importo il metodo pyplot della libreria matplotlib
Si tratta di una semplice funzione di plotting dei dati.
import matplotlib.pyplot as plt
Scrivo il titolo del grafico, la posizione della legenda, le label sull'asse delle ascisse (x) e delle ordinate (y).
plt.title('SVM con Iris')
plt.xlabel('sepal lunghezza [cm]')
plt.ylabel('petal lunghezza [cm]')
plt.legend(loc='upper left')
Infine visualizzo il grafico tramite il plotting con il metodo show()
plt.show()
Sullo schermo viene visualizzato il diagramma cartesiano a due dimensioni con gli esempi del dataset di training ( insieme di addestramento ) e i confini della classificazione tramite il metodo SVM.
La linea di demarcazione individua tre regioni di dati colorate automaticamente in modo diverso in base alla classificazione dell'algoritmo.
I colori e le forme dei singoli esempi, invece, sono determinanti dall'insieme di test.
Così facendo, posso rappresentare graficamente il risultato di qualsiasi altro classificatore ( es. ada ).
E così via




