Come fare l'analisi degli errori con scikit learn
Quando creo un modello di classificazione con il machine learning supervisionato, una delle prime analisi è lo studio dell'accuratezza.
Cos'è l'accuratezza? L'accuratezza (accuracy) è un indicatore sintetico che riassume la capacità del modello di rispondere correttamente. In genere si utilizza la funzione accuracy_score(). Non è comunque l'unico indicatore. Ce ne sono anche altri.
Tuttavia, l'accuratezza non è sufficiente a capire i problemi del modello, perché non approfondisce le eventuali cause del malfunzionamento.
Quando il modello funziona male devo studiare anche gli altri indicatori (precision, recall , f1-score).
Come fare?
In scikit learn c'è una funzione apposita che mi permette di calcolarli tutti.
Si chiama classification_report.
Un esempio pratico
Per prima cosa carico le librerie di scikit learn, un dataset e un algoritmo di classificazione.
In questo esempio opto per il dataset didattico Iris e il classificatore Perceptron.
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
Richiamo il dataset iris, lo assegno a due variabili X (features) e y (target).
dataset = load_iris()
X=dataset['data']
y=dataset['target']
Suddivido il dataset delle features (caratteristiche) e del target (y) in training e test.
Il dataset di test è composto dal 30% degli esempi complessivi.
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
A questo punto faccio girare il classificatore per creare il modello tramite la funzione fit().
In questo caso utilizzo il Perceptron come algoritmo di classificazione ma qualsiasi altro classificatore andrebbe bene.
model = Perceptron()
model.fit(X_train, y_train)
Una volta costruito il modello, calcolo le previsioni sulle caratteristiche di test (X_test) con la funzione predict().
Salvo le previsioni nella variabile p_test.
p_test = model.predict(X_test)
Infine, verifico l'accuratezza confrontando le previsioni con i dati corretti (y_test) con la funzione accuracy_score().
acc = accuracy_score(y_test, p_test)
print(acc)
L'accuratezza del modello è
0.9333333333333333
Vuol dire che il modello risponde correttamente nel 93% dei casi.
Dove sbaglia il modello?
Per saperlo utilizzo la funzione classification_report.
Confronto le previsioni (p_test) con i risultati corretti (y_test) tramite la funzione classification_report().
Poi stampo il risultato .
report=classification_report(p_test, y_test)
print(report)
Questa funzione produce una reportistica molto più dettagliata.
In una sola schermata visualizza la precisione (precision), il recall e l'f1-score per ogni classe.
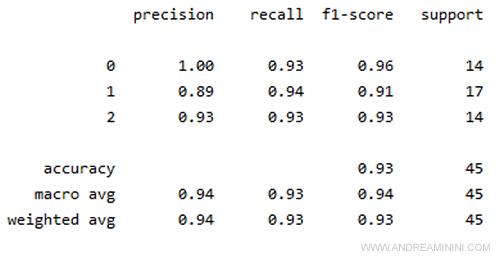
In questo caso ci sono solo tre classi (0, 1, 2) ossia le classi di fiori Iris: Setosa, Versicolor e Virginica.
Nella colonna support è indicato il numero degli esempi di ogni classe.
Esempio. La precisione (precision) della classe 0 è 1.00. Vuol dire che il modello ha classificato correttamente la classe 0 al 100%. La precisione della classe 1 è invece 0.89 mentre la precisione della classe 2 è 0.93. Pertanto, il modello sbaglia a classificatore soprattutto gli esempi della classe 1 e 2. E' un semplice esempio di analisi degli errori. A cosa serve? Grazie a questa informazione posso migliorare il modello, aggiungendo nel dataset di training altri esempi della classe 1 e 2, per produrre un nuovo modello (forse) più accurato del precedente.
Nella parte bassa del report sono visualizzati i dati sintetici per tutte le classi.
Tra i quali anche l'accuratezza (accuracy) che già conosco (0.93).
La matrice di confusione
Per saperne di più sugli errori del modello posso utilizzare anche la matrice di confusione (confusion matrix).
E' uno strumento grafico della libreria scikitplot.
A cosa serve la matrice di confusione? Mi permette di capire quali sono le risposte sbagliate del modello. E' un'ulteriore informazione utile che completa l'analisi degli errori iniziata con il classification_report.
Importo le librerie scikitplot e matplotlib.
import scikitplot as skplt
import matplotlib.pyplot as plt
Elaboro la matrice di confusione con la funzione plot_confusion_matrix() passandogli il vettore delle predizioni p_test e delle risposte corrette y_test.
skplt.metrics.plot_confusion_matrix(p_test,y_test)
Infine visualizzo la matrice con la funzione show() di matplotlib.
plt.show()
Sullo schermo viene mostrata la matrice di confusione del modello.
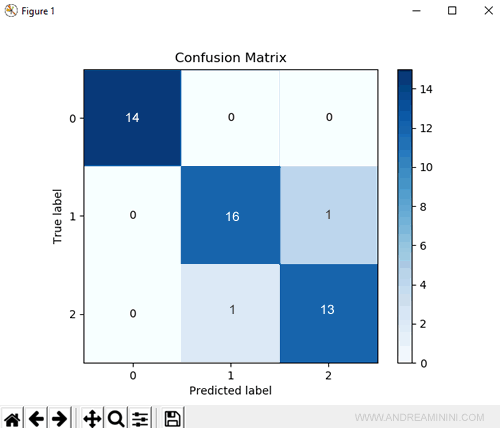
Come si legge la matrice di confusione?
Sulle colonne sono indicate le classi previste dal modello (Predicted label) mentre sulle righe le classi corrette (True label) del dataset.
La diagonale principale della matrice indica le previsione corrette del modello (positive).
Le altre celle indicano le previsioni sbagliate (negative).
Esempio. Ad esempio, nel dataset ci sono 14 risposte corrette (True label) che indicano la classe 0 e il modello le prevede tutte.
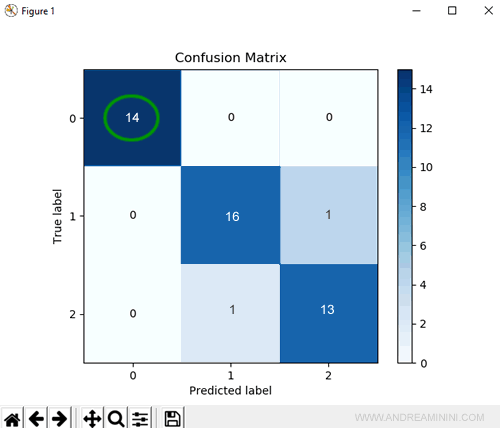
Nel dataset ci sono 17 risposte corrette (True label) che indicano la classe 1 ma il modello risponde correttamente solo 16 volte perché 1 volta prevede (sbagliando) la classe 2.
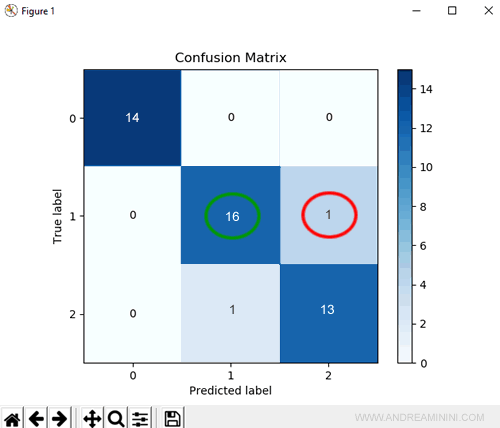
Infine, nel dataset ci sono 14 risposte corrette (True label) che indicano la classe 2 ma il modello risponde correttamente solo per 13 volte perché 1 volta prevede (sbagliando) la classe 1.
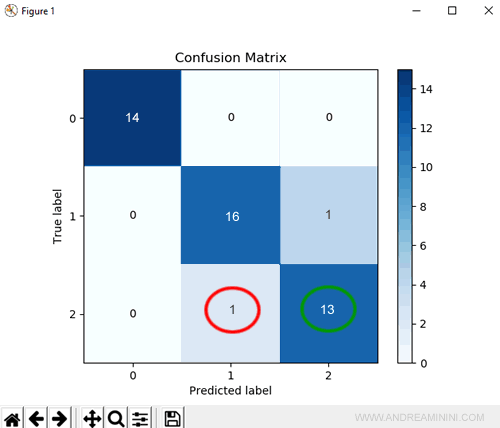
Grazie alla matrice di confusione riesco a capire in quali classi sbaglia il modello e quali sono le risposte sbagliate.
E così via.




