StandardScaler su Scikit-learn
Per elaborare la riduzione in scala dei dati dell'insieme di training e di test, nel modulo scikit-learn di python posso usare la classe StandardScaler().
Cos'è la riduzione di scala? La riduzione di scala standardizza la serie di valori. La standardizzazione è un metodo di riduzione di scala che trasforma una serie di valori in una distribuzione normale standard con media uguale a zero e devianza standard uguale a uno.
Un esempio pratico
Ho un insieme di training ( X_train ) e un insieme di test ( X_test ). Inizialmente, i due insiemi contengono i valori originali degli attributi.
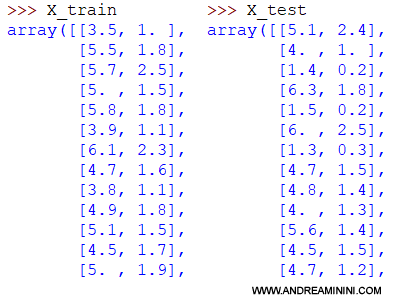
Per standardizzarli richiamo la classe StandardScaler.
- from sklearn.preprocessing import StandardScaler
- sc = StandardScaler()
- sc.fit(X_train)
- X_train_std = sc.transform(X_train)
- X_test_std = sc.transform(X_test)
Nella riga 1 carico il modulo ScandardScaler da sklearn.
Nella riga 2 richiamo la classe StandardScaler(), inizializzo un oggetto e lo assegno alla variabile sc.
Nella riga 3 uso il metodo fit() per stimare la media del campione e la deviazione standard dell'insieme di training (X_train).
Nella riga 4 uso il metodo transform() standardizzare i dati dell'insieme di training (X_train) usando i parametro appena calcolati dal metodo fit. Poi salvo il risultato nella variabile X_train_std.
Cos'è la standardizzazione? La standardizzazione consiste nel sottrarre la media (μ) da ogni valore (x) del vettore e dividere la differenza per la devianza standard (σ).
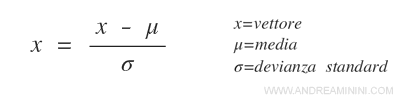
Nella riga 5 applico di nuovo il metodo transform()con gli stessi parametri anche all'insieme di test (X_test) per renderlo omogeneo e confrontabile con l'insieme di training. Poi salvo il risultato nella variabile X_test_std.
I dati standardizzati
Lo script crea due nuovi insiemi di training ( X_train_std ) e di test ( X_test_std ) con i dati standardizzati.
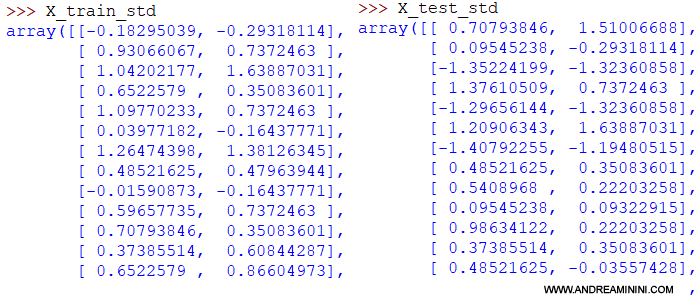
A questo punto, dopo la standardizzazione, avvio l'algoritmo di addestramento direttamente sui dati standardizzati dell'insieme di training ( X_train_std).
Infine, verifico l'accuratezza del modello usando i dati standardizzati dell'insieme di test (X_test_std).
Perché?
Le performance del processo di learning sono generalmente superiori quando l'algoritmo lavora su dati standardizzati.
Esempio. Ho usato il perceptron su dati normali del dataset Iris ottenendo il 57% di accuratezza. Lo stesso processo sui dati standardizzati ha raggiunto il 97% di accuratezza a parità di iperparametri. C'è quindi un bel vantaggio.




