Come vettorizzare i testi in python
Nel linguaggio python per vettorizzare un testo uso la classe CountVectorizer() del modulo scikit learn.
Cos'è la vettorizzazione? Spesso è utile trasformare le parole di un testo in un numero. In questo modo, una frase si trasforma in un vettore numerico. Questo processo è detto vettorizzazione del testo.
Un esempio pratico
Importo la funzione array di numpy
from numpy import array
Creo un vettore contenente delle stringhe (frasi).
diz = array( [
'Oggi è una bella giornata.',
'Oggi non è una bella giornata.',
'Oggi sta piovendo.',
])
Importo la classe CountVectorizer() da scikit learn
from sklearn.feature_extraction.text import CountVectorizer
Creo un vettorizzatore che considera le parole prese singolarmente
vettorizzazione=CountVectorizer(ngram_range=(1,1))
Per prendere anche le parole prese a coppie, modifico il parametro da (1,1) a (1,2).
Infine, uso i metodi fit() e transform() per vettorizzare e trasformare il vettore.
Assegno il risultato alla variabile diz.
vettorizzazione.fit(diz)
diz = vettorizzazione.transform(diz)
Poi visualizzo il risultato
print(diz)
Il risultato è una matrice sparsa.
(0, 3) 1
(0, 6) 1
(0, 0) 1
(0, 1) 1
(1, 3) 1
(1, 6) 1
(1, 0) 1
(1, 1) 1
(1, 2) 1
(2, 3) 1
(2, 5) 1
(2, 4) 1
In pratica, l'algoritmo crea una matrice.
Per vederla nella sua tipica forma a griglio uso il metodo todense().
print(diz.todense())
In questo modo posso vedere tutte le righe e le colonne della matrice.
La matrice sparsa, invece, visualizza solo le celle con elemento non nullo.
[[1 1 0 1 0 0 1]
[1 1 1 1 0 0 1]
[0 0 0 1 1 1 0]]
Questa forma è equivalente, si capisce più facilmente ma ha una dimensione notevolmente superiore alla precedente perché include anche le informazioni non rilevanti ossia gli zeri.
Cos'è successo?
Ogni frase del corpus diventa una riga di una matrice.
L'algoritmo di vettorizzazione crea una feature (colonna) per ogni parola che incontra nei testi.
Per capire il significato delle colonne uso il metodo get_feature_names()
print(vettorizzazione.get_feature_names())
L'ourtput è
['bella', 'giornata', 'non', 'oggi', 'piovendo', 'sta', 'una']
Vuol dire che la prima colonna della matrice (0) è la parola 'bella', la seconda colonna (1) è la parola 'giornata', la terza colonna (2) è la parola 'non', ecc.
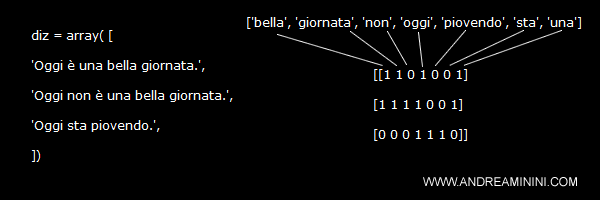
Ogni riga (frase) della matrice ha il valore 1 nelle rispettive colonne dei termini che compaiono nella frase.
Attenzione. Se una parola compare due volte in una frase, la rispettiva colonna ha il valore 2. Se compare 3 volte ha valore 3, e così via.
Ho trasformato il corpus in valori numerici.
A cosa serve?
Questa forma equivalente del corpus è molto più facile da usare negli algoritmi di addestramento (machine learning).
Ogni numero indica una e una sola parola.
Per trasformare i vettori numerici nelle rispettive parole uso la funzione inverse_transform().
print(vettorizzazione.inverse_transform(diz))
Il risultato è il seguente:
[array(['oggi', 'una', 'bella', 'giornata'], dtype='<U8'),
array(['oggi', 'una', 'bella', 'giornata', 'non'], dtype='<U8'),
array(['oggi', 'sta', 'piovendo'], dtype='<U8')]
Devo però fare attenzione a un errore molto frequente quando si lavora con fit e transform.
Le associazioni ai numeri sono create tramite il metodo fit(). Quindi, se rilancio il metodo fit() le associazioni cambiano.
Il metodo transform() invece può essere usato più volte perché non le modifica.
E così via.




