La firma lessicale del copywriter nel testo
Ogni copywriter ha una propria firma lessicale ( o impronta lessicale ) che lascia nel testo scritto senza esserne consapevole. Nel text mining questa firma è caratterizzata da regolarità statistiche e può essere intercettata da una procedura algoritmica.
Come calcolare la firma lessicale nel testo
E' necessario analizzare l'insieme delle frasi e delle parole contenute nel documento. I termini devono essere poi confrontati con quelli di un corpus preso come riferimento. Il confronto permette di stabilre se la distribuzione dei termini è normale oppure anomala.
- La distribuzione normale dei termini caratterizza i testi scritti da persone differenti. Ogni persona scrive in modo diverso.
- La distribuzione anomala identifica i testi scritti dalla stessa persona. Ad esempio l'eccessiva ripetizione delle combinazioni di vocaboli e di locuzioni, presenti in più testi, è un fenomeno poco naturale che rivela la stessa mano dello scrittore.
Tuttavia, una semplice analisi grammaticale e letterale del testo non ci fornisce alcuna informazione utile. Non è sufficiente per questo scopo.

E' necessario normalizzare il documento in modo opportuno.
L'eliminazione dei termini specifici
Il primo passo della normalizzazione consiste nell'eliminare dal testo tutti i termini specifici, quelli relativi all'argomento trattato nel testo. E' l'operazione opposta rispetto a quella che si compie normalmente in un processo IR.
Alcuni termini sono presenti soltanto nei documenti che trattano un particolare argomento ( es. omeopatia => salute ).
Perché i termini specifici vanno eliminati? I giornalisti che scrivono su un particolare argomento utilizzano la terminologia specifica della materia ( termini economici, medici, legali, ecc. ). La presenza di questi termini non consente di risalire all'autore del pezzo poiché tutti i copywriter li utilizzano.
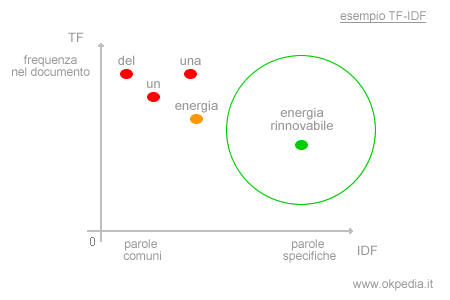
I termini specifici e le parole chiave ( keyword ) sono riconoscibili tramite il calcolo dell'indicatore IDF ( Inverse Document Frequency ) oppure TF-IDF. Una volta individuate, vanno rimosse dal testo.
La normalizzazione delle locuzioni e dei segmenti
Prima di eliminare le parole chiave del discorso è consigliabile scansionare i documenti allo scopo di individuare i segmenti lessicali delle parole composte.
Cos'è un segmento lessicale? E' una combinazione di due o più parole che si presentano in un particolare ordine sequenziale e ha un proprio significato semantico nel dizionario oppure è una locuzione. Ad esempio, "in qualche modo", "pannelli solari", ecc.
I segmenti lessicali vanno trattati come un unico termine. In sostituzione dello spazio tra le singole parole si utilizza il simbolo underscore ( _ ) come carattere di separazione.

A questo punto, si può procedere con l'eliminazione delle parole e dei termini specifici del discorso.

Al termine di questa operazione, ciò che resta è un testo composto soltanto da parole e termini di uso generale e comune. Le cosiddette stop-word.

Nota. Sono dette "stop-word" perché in un processo di searching IR non sono rilevanti. A volte sono eliminate durante la fase di indicizzazione del documento. Questo accadeva soprattutto nei motori di ricerca di prima generazione.
La conversione delle parole alla forma radice
Il passo successivo consiste nella trasformazione dei verbi all'infinito. Questo permette di considerare i predicati verbali con tempo e persona diversa come un unico termine.

Gli altri termini del testo sono invece trasformati nella loro forma flessa o radice.
Esempio. Il termine "sicuramente" viene sostituito con "sicur-". La forma flessa raggruppa un insieme più ampio di termini ( sicuro, sicura, sicuramente, ecc. ).
Questo evita di considerare come parole diverse il singolare e il plurale delle stessa parola, oppure le variazioni di genere ( maschile/femminile ) dello stesso termine.

Per ottenere la forma radice si può utilizzare un semplice algoritmo di stemming. E' consigliabile non usare lo stemming sui predicati verbali se sono stati già trasformati all'infinito.
Eliminazione della punteggiatura. L'ultimo passo del processo di normalizzazione del testo è l'eliminazione dei segni di punteggiatura ( virgola, punto, punto e virgola, due punti, ecc. ).
L'analisi delle stop word
I documenti normalizzati sono pronti per essere confrontati. Nell'analisi delle stop-word si calcola quali e quanti sono i termini ricorrenti su tutti i documenti, quelli che compaiono su più documenti.
Quando le stop-word ricorrenti sono molte, aumenta la probabilità che il testo sia stato scritto dalla stessa persona ( scrittore o copywriter ).

In particolar modo, si confronta la distribuzione dei termini ripetuti nei documenti del corpus con una distribuzione naturale o normale, presa come riferimento.
Se lo scostamento è elevato, l'impronta lessicale nei documenti del corpus è probabilmente la stessa.
L'analisi dei segmenti
Un'altra informazione utile viene fornita dai segmenti di testo. Generalmente, uno scrittore tende a utilizzare sempre gli stessi segmenti e le stesse locuzioni.

La presenza ripetuta degli stessi segmenti lessicali nel corpus dei documenti è un altro indizio che i testi sono stati scritti dalla stessa mano.
A cosa serve la firma lessicale
E' utile per riconoscere lo stesso autore dietro più documenti per contrastare il fenomeno dello spam engine lessicale, i private blog network e i guest post sui motori di ricerca.
Può essere utilizzata anche come elemento di prova per attribuire la vera paternità di un articolo a uno scrittore, nelle controversie legali sui casi di plagio. In particolar modo, quando non è ben definito il copyright e il diritto di autore del pezzo.




