Le keyword proof
Le keyword proof sono i termini che descrivono idealmente un particolare oggetto di conoscenza. Quando un testo contiene al suo interno molte keyword proof su un oggetto, è molto probabile che stia affrontando quell'argomento. Questi termini sono anche conosciuti come proof term o parole chiave di prova.
Cosa significa proof term
Si chiamano proof term, ossia parole chiave di prova o di esistenza, perché il search engine le utilizza per verificare la vicinanza di un documento a un particolare tema.
La presenza di queste parole ( term ) nel testo è la prova ( proof ) che il contenuto è sufficientemente accurato su un particolare ambito del sapere.
Come funzionano le keyword proof
Come prima cosa, l'algoritmo del search engine controlla i termini nel testo del documento e l'appartenenza ai campi semantici dei temi nella propria base di conoscenza.
1] La verifica di esistenza dei termini
A ciascun tema ( topic ) è associato un elenco di termini pertinenti. Ad esempio, per il topic "ottimizzazione search engine" l'elenco dei termini rilevanti potrebbe essere il seguente:
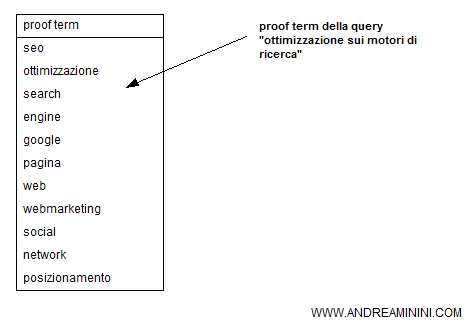
Se questi termini esistono nel documento, allora il documento è vicino all'argomento ( topic ) della lista. Questa fase di controllo è detta di esistenza dei termini.
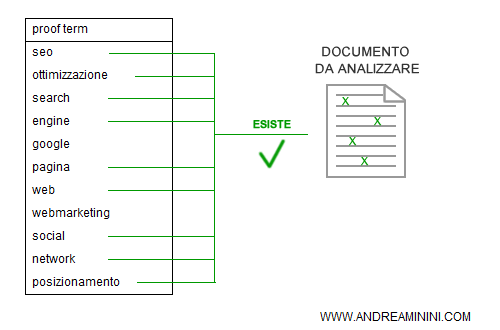
2] La distribuzione della frequenza dei termini
Tuttavia, per individuare un legame tra il documento e un tema non è sufficiente che nel testo vi siano tutte le parole chiave di prova su quell'argomento specifico, è anche necessario che le chiavi di prova siano distribuite in modo normale.
Oltre a verificare la presenza delle occorrenze nel testo, il search engine analizza anche la distribuzione di frequenza dei termini nel documento.
L'algoritmo prende in considerazione il valore medio ( AF ) e il valore massimo ( MF ) della frequenza del termine nei documenti della sua knowledge base che trattano quel particolare tema o topic.
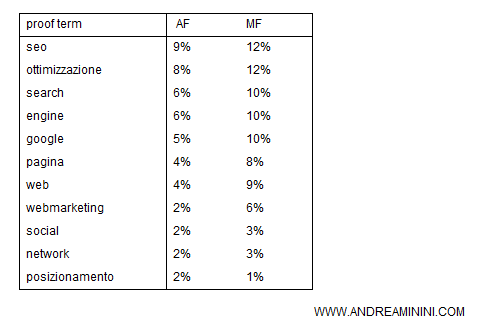
A questo punto, il search engine calcola la frequenza dei termini nel documento ( DF ) e la confronta con la distribuzione ideale ( AF / MF ).
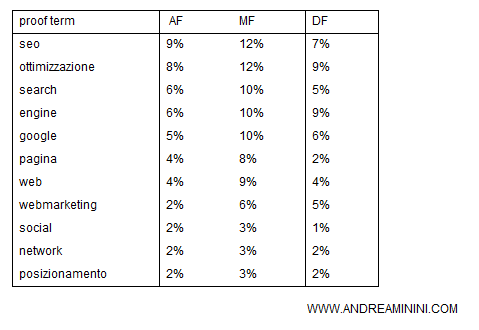
Se il search engine nota dei picchi anomali nella distribuzione del testo ( DF ) rispetto alla distribuzione normale, quella presa come riferimento, allora il filtro scarta il documento dai risultati della query.
Un caso di distribuzione normale della frequenza delle proof term
Nel seguente esempio viene mostrato il caso di un testo con distribuzione normale. Tutti i proof term sono presenti nel testo entro la frequenza massima di riferimento. Il filtro antispam non scatta.
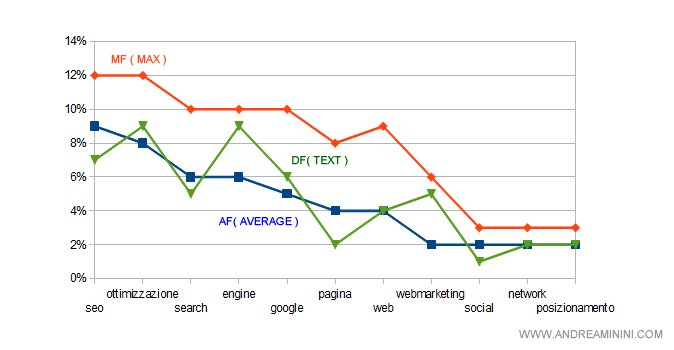
Questo conferma che il testo è un contenuto pertinente nei confronti della query digitata dall'utente.
Un caso di distribuzione anomala della frequenza delle proof term
Nel seguente esempio è rappresentato il caso opposto, quello di una distribuzione anormale ( anomala ) delle frequenze. In questo caso il termine "engine" è presente nel testo con una frequenza ( DF ) superiore a quella massima ( MF ) di riferimento. In questo caso scatta il filtro anti-spam.
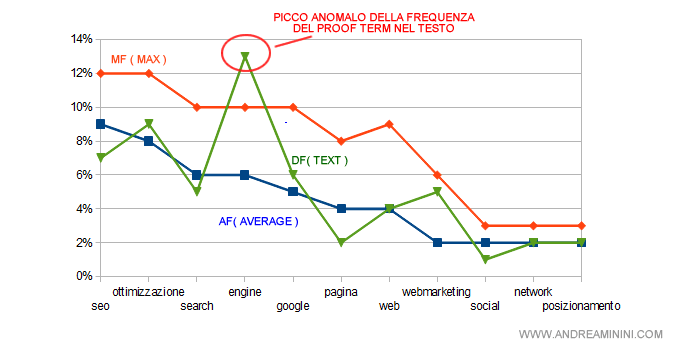
Nota. Quest'ultimo caso potrebbe nascondere un tentativo di spam o di keyword stuffing nel testo. Per questo motivo il filtro anti-spam del processo IR ( Information Retrieval ) scarta il documento dalla selezione.




